Strong Consistency vs Eventual Consistency
Exploring the difference between Strong and Eventual Consistency

What is Consistency?
Consistency, in the context of distributed systems and databases, refers to the property that ensures all replicas or nodes in the system maintain the same view of the data, adhering to a specified set of rules or constraints. It ensures that the data remains coherent and correct throughout the system, even though the data may be distributed across multiple locations or nodes.
In a consistent system:
Read consistency:
Any read operation on a piece of data will return the most recent write value or a value that satisfies specific consistency guarantees, irrespective of which node the read request is directed to.Write consistency:
When a write operation is performed, the data will be propagated to all relevant nodes in the system, ensuring that all replicas are updated with the latest value before the operation is considered successful.
Why is Consistency needed?
Consistency ensures that all users, applications, or services interacting with the system see a unified and up-to-date view of the data, regardless of which node they access. There are several key reasons why consistency is crucial:
Data correctness: Consistency guarantees that data remains accurate and free from conflicting values. Inconsistent data could lead to incorrect decisions, calculations, or actions, which can have serious consequences in critical applications such as financial systems, healthcare, or e-commerce.
Data coherency: Consistency ensures that related data items or records stay logically coherent. For example, in a banking application, if a user’s account balance is updated, it should be immediately reflected in all replicas to avoid scenarios where the user may withdraw money from one replica and later find a different balance in another replica.
Reliable operations: Strong consistency ensures that operations like read-modify-write sequences are performed correctly, without the risk of multiple concurrent modifications causing data conflicts.
System predictability: Consistent systems behave more predictably and are easier to reason about. Developers can rely on data consistency guarantees when designing and implementing applications.
Transactional integrity: In many systems, transactions involve multiple operations that must be treated as an atomic unit. Consistency ensures that either all operations within a transaction are executed successfully, or none of them are, preventing partial or incomplete updates.
Collaboration and scaling: Distributed systems often involve multiple nodes working together to handle user requests and data updates. Consistency ensures that these nodes can cooperate effectively and produce reliable results as if they were a single, cohesive system.
While consistency is vital, it’s essential to understand that achieving strong consistency in distributed systems can come at the expense of increased latency and reduced availability. Strong consistency may require additional coordination mechanisms that slow down operations. Therefore, choosing the appropriate consistency model involves striking a balance between data correctness and system performance, based on the specific requirements of the application and use case. Different systems may opt for eventual consistency or other weaker consistency models if absolute real-time consistency is not necessary for their functionality.
Strong Consistency
Strong consistency is a property in distributed systems that ensures that all nodes in the system see the same data at the same time, regardless of which node they are accessing. In other words, when a write operation is performed, all subsequent read operations from any node will return the most recent write value. This guarantees that there is a linear ordering of operations, and the system behaves as if it were a single, coherent entity.
To illustrate strong consistency, let’s consider an example of a simple distributed key-value store with three nodes (A, B, and C) and two clients (Client 1 and Client 2). Each node can handle both read and write operations. The data replication is done synchronously, meaning that every write must be propagated to all nodes before a response is sent back to the client.
Initial State:
Node A: key1=10
Node B: key1=10
Node C: key1=10
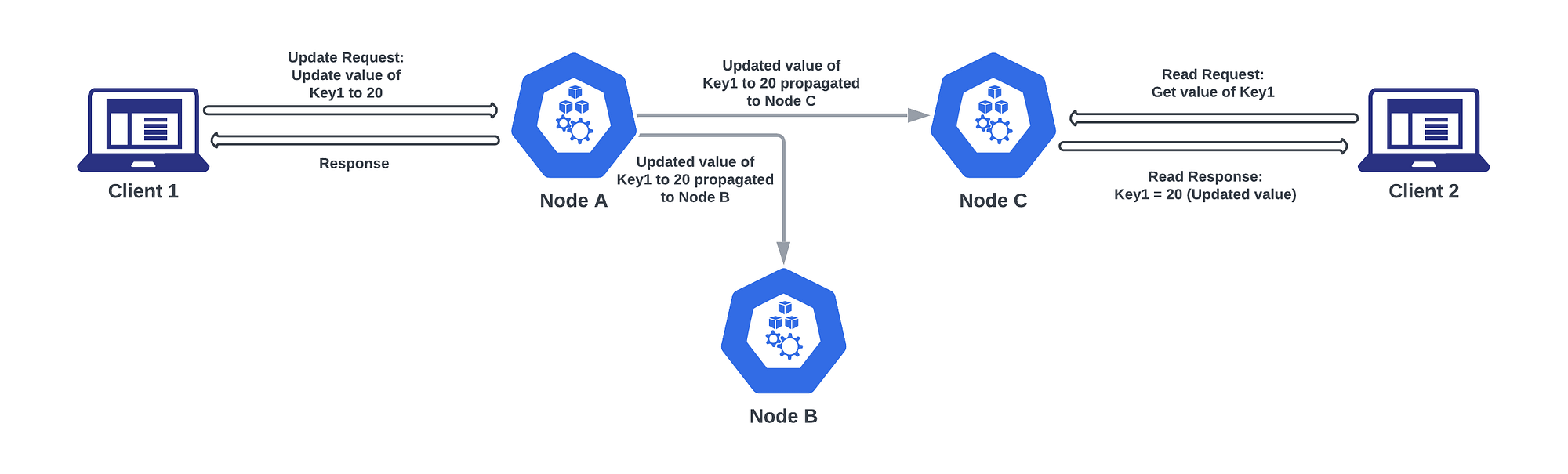
Let’s take the following scenario and try to understand how strong consistency would behave:
Client 1 sends a write request to Node A to update key1 to 20.
Node A receives the request, updates the value to 20, and propagates the update to Nodes B and C.The response from Node A is sent back to Client 1 and now Client 2 immediately sends a read request to Node C to get the value of key1.
Since the system follows strong consistency, Node C has already received the update from Node A and reflects the latest value of key1, which is 20.Node C responds to Client 2 with the value 20.
In this example, strong consistency ensures that both clients (Client 1 and Client 2) see the updated value of key1 (20) after the write operation, even though they accessed different nodes (Node A and Node C). This property guarantees that the system behaves as a single, coherent entity, and there is no possibility of one client seeing an outdated value while another client observes the updated value.
Eventual Consistency
Over time, the system converges towards consistency, but during the transient period, users accessing different data centers may observe different versions of the data. This is the characteristic behavior of eventual consistency. While the system guarantees that updates will eventually be propagated and all nodes will reach a consistent state, there can be temporary discrepancies between nodes at any given moment.
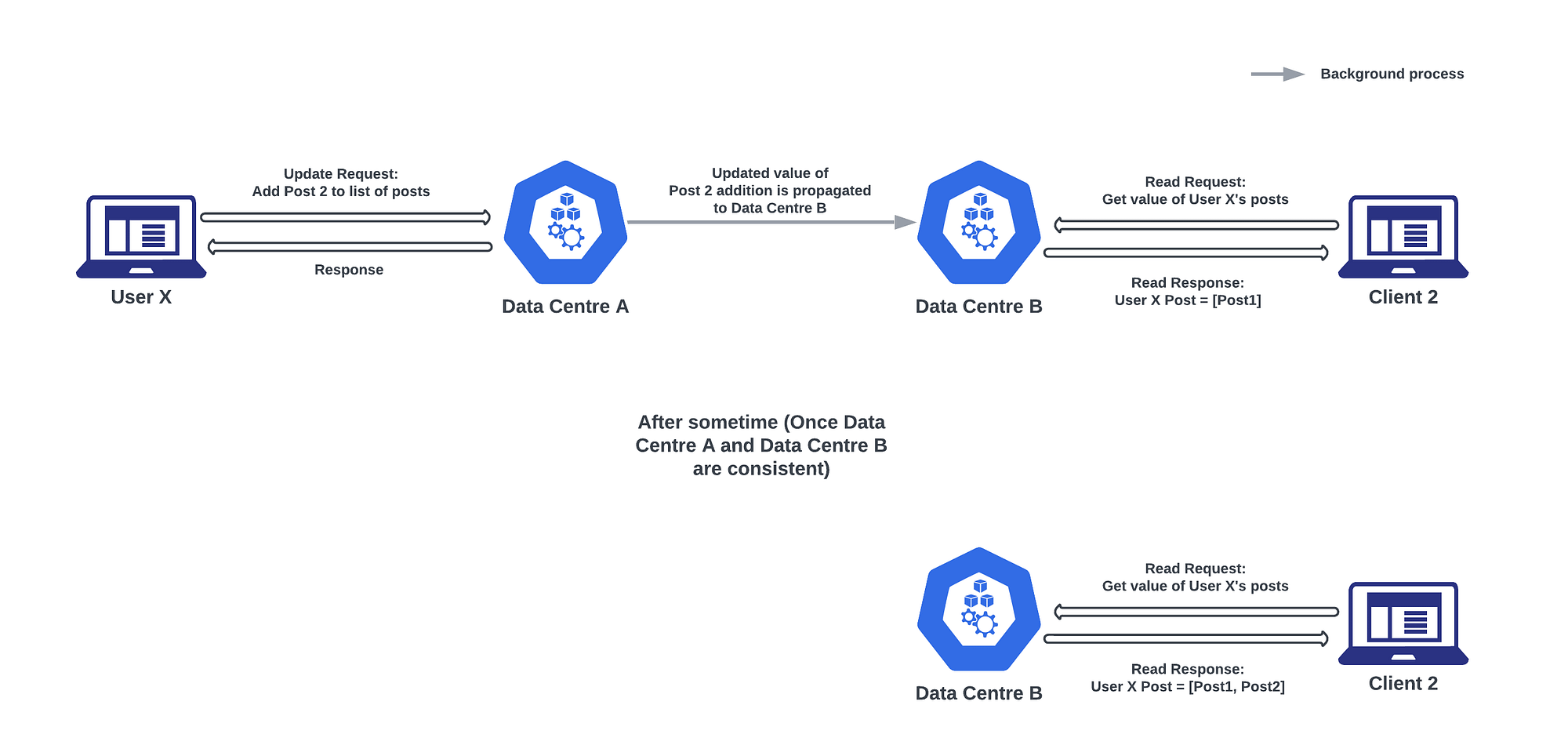
Consider a popular social media platform where users can post messages, and these messages are replicated across multiple data centers to ensure high availability and fault tolerance. Each data center contains its copy of the user’s posts, and they are synchronized asynchronously to maintain eventual consistency.
Initial State:
Data Center A: User X’s posts = [“Post 1”]
Data Center B: User X’s posts = [“Post 1”]
Scenario:
User X posts a new message Post 2 from their mobile app. The request is sent to Data Center A, where it is immediately stored in the local database. However, the replication process to Data Center B is asynchronous, and the update is not yet propagated.
User Y, who is in a different location, accesses Data Center B’s servers to view User X’s posts. Currently, Data Center B has not received the update about Post 2, so it returns User X’s posts as [“Post 1”].
Meanwhile, the replication process is ongoing in the background. After a short period, Data Center B receives the update and adds Post 2 to User X’s posts.
User Y now decides to refresh their feed to see User X’s posts. Data Center B now has the updated version of User X’s posts and User Y is thus able to see Post 2.
Tradeoffs between Strong Consistency and Eventual Consistency
The choice between strong and eventual consistency involves significant tradeoffs that depend on the specific requirements and characteristics of a distributed system. Let’s explore the key tradeoffs between these two consistency models:
1. Data Accuracy:
- Strong Consistency: Ensures that all nodes see the same data at the same time, guaranteeing immediate data accuracy and integrity. Users can always read the most recent write, and there are no stale or conflicting values.
- Eventual Consistency: Temporarily allows nodes to be inconsistent, which may result in stale data being read until convergence occurs. This introduces the possibility of users seeing outdated values during the convergence process.
2. Performance:
- Strong Consistency: Achieving strong consistency often involves increased coordination and communication among nodes, leading to higher latency for read and write operations. The system may experience more contention and slower responses due to the need for synchronous updates across replicas.
- Eventual Consistency: The asynchrony of write propagation and reduced coordination overhead allows for lower latency and higher throughput for read and write operations. The system can scale more easily and handle larger numbers of concurrent requests.
3. Availability:
- Strong Consistency: During network partitions or node failures, maintaining strong consistency may lead to unavailability if the required number of replicas cannot be reached for read or write operations. The system prioritizes consistency over availability in such scenarios.
- Eventual Consistency: Emphasizes availability during network partitions and node failures. Since replicas can operate independently, the system remains available for read and write operations even if some nodes are unreachable.
5. Use Cases:
- Strong Consistency: Best suited for scenarios where data integrity and consistency are critical, such as financial systems, e-commerce platforms, and critical business applications.
- Eventual Consistency: Well-suited for applications where real-time consistency is not vital and system availability and scalability are more important, such as social media platforms, content distribution networks, and collaborative systems.
Choosing between strong and eventual consistency depends on the specific needs of the application and its users. Some systems may adopt a hybrid approach, selectively applying strong consistency to certain critical data and eventual consistency to less critical or non-critical data, striking a balance between data accuracy, performance, and availability. The decision requires careful consideration of the tradeoffs to meet the desired requirements and constraints of the distributed system.
Finishing off with the article here. I really hope I made the article worth your while and you learned a great deal from it.
More than happy to address any improvements and suggestions. Please feel free to drop a comment.